
什么是大数据?
从字面的意思来看,大数据就是大量的数据。业界一般认为数据量达到普通的设备存不下,算不动的程度,就可以称之为大数据了。
「大数据又称为巨量资料,指的是在传统数据处理应用软件不足以处理的大或复杂的数据集的术语。」
—— 维基百科
「大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。」
—— 百度百科
「大数据由巨型数据集组成,这些数据集大小常超出人类在可接受时间下的收集、庋用、管理和处理能力。」
—— MBA智库
从上面的几种定义可以看出,首先,数据量要大到常规方式无法处理的程度;再者,大数据作为信息资产,需要通过处理从中获取价值信息。
大数据到底有多大?
普通个人电脑所能存储的数据,一般是几百个GB到几个TB的级别。
例如,常见的固态硬盘,512GB就已经比较大了;常见的机械硬盘,可达1TB/2TB/4TB的容量。
表达数据容量的KB,MB,GB和TB之间的关系,大家应该都很熟悉了:
KB(Kilo Byte)— 千字节,也就是1024B
MB(Mega Byte)— 兆字节,也就是1024KB
GB(Giga Byte)— 吉字节,也就是1024MB
TB(Tera Byte)— 太字节,也就是1024GB
而大数据是什么级别呢?PB/EB级别。其实就是在TB的基础上每一级接着乘以1024。
PB(Peta Byte)— 皮字节,也就是1024TB
EB(Exa Byte)— 艾字节,也就是1024PB
ZB(Zetta Byte)— 泽字节,也就是1024EB
YB(Yotta Byte)— 尧字节,也就是1024ZB
上述的这些大的单位在日常生活中几乎接触不到,而且常人也已经无法直观地感受到这些单位能大到什么让人吃惊的程度。下面我们举个简单的例子来说明。
一本《红楼梦》:纯文本(未压缩),约2MB
一张1200万像素的照片(未压缩):约34MB
一部90分钟的电影(H.264编码):约2.5GB(也就是2500MB)
这样算下来,一块1TB的硬盘大约可以存储50万本电子书,3万张图片,400部电影。假定三天时间看完一本书,这50万本就需要4000多年才能看完。
1PB的容量大约可存储5亿本书,3千万张图片,或40万部90分钟的电影。看书的时间过于夸张就不说了,这些电影也需要持续近140年时间才能看完。
1EB这个单位的庞大已经超乎了人们的想象,仅仅存放这些数据需要大约2000个机柜的存储设备。
如果并排放这些机柜,可以连绵1.2公里那么长。如果摆放在机房里,需要21个标准篮球场那么大的机房,才能放得下。
真的有企业会产生如此海量的数据吗?
事实上,阿里、百度、腾讯这样的互联网巨头,因为其拥有数亿的用户,这些海量用户产生的数据量早已超越PB级,接近EB级。
大数据是怎样产生的?
随着互联网,物联网的发展,万事万物皆可连接,皆可源源不断地产生数据,从涓涓细流汇聚成汪洋大海。
经过移动互联网的大爆发,中国的上网用户数已经约等于智能手机的用户数,通过4G网络随时连接,实时在线。
这些用户在手机上的每一次滑动和点击,都会被各式各样的APP上传并存储,以及在微博,微信,知乎,抖音等各种社交或者UGC类APP上创作的文本,图片和视频,形成海量的数据。
物联网方面也不遑多让。据GSMA智库预测,到2025年全球将会有18亿移动物联网连接(总共31亿蜂窝物联网连接),以及138亿工业物联网连接,其中63亿在亚太地区和中国,占总数的65%。
如果放在以前,计算机的硬件(存储,计算)等资源还很金贵的情况下,这些数据只能是经过简单汇总之后就被丢掉。
然而随着技术的发展,计算机硬件的存储和计算能力越来越强,越来越不值钱,这些原本被认为食之无肉弃之有味数据才能被大量存储和处理,并挖掘价值。
目前微信拥有11亿的用户,每天发送数百亿条消息,还有朋友圈,支付,扫一扫,摇一摇等多种行为都存储在微信的后台。
如果要从这些海量数据中分析所有微信用户的行为习惯,比如每天的使用时长,偏好发语音还是文字,对哪些类型的公众号感兴趣等数据就没有那么简单了。这就是各种大数据技术诞生及发展的驱动力。
大数据有哪些特点?
由于大数据的描述众说纷纭,4个V,5个V,乃至8个V的说法都有。本文就简采用IBM的4V说:大量(Volume),高速(Velocity),多样(Variety),价值(Value)。
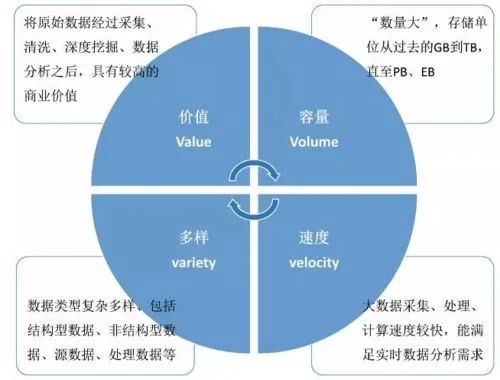
1、大量:这一点是大数据最基础的属性,前面讲过了。也就是说:大数据分析的是所有样本,不是随机抽样,因此可进行多维度,更详细的分析。
2、高速:数据产生地快,对分析和使用的速度要求也很高。如果像刻舟求剑一样,分析地虽然精确,但耗时过长,以至于结论早已过时,终究是没有用处的。
试想一下,在网上买书的时候,系统会根据目前浏览的书来智能推荐用户还可能感兴趣的其他书,这个是要求秒级响应的。如果过了半小时才算出结果来,用户很可能早都购物结束了。
3、多样:数据的来源多种多样,格式不一,既有传统的结构化数据,更多的则是非结构化数据。
结构化数据就是可以按照预定义的关系模型来存储的数据。
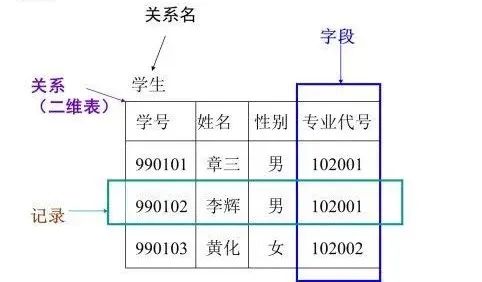
非结构化数据指的那些没有固定格式,内容需要分析识别才知道的数据,一般就是网页,图片,音频,视频等数据。这些数据占比可达80%以上。
也就是说,大数据不是精确性,而是混杂性,只要这些数据拥有可供挖掘的信息,就都来者不拒。
4、价值:数据虽多,但价值密度很低,必须经过大量的分析和提取,才能较为准确地发现其中蕴藏的规律。
据不完全统计,公安机关全国每年需要存储的数据量高达3.3EB,结合视频监控和人脸识别,实现犯罪嫌疑人的快速识别和实时布控。
中国的犯罪率是很低的,收集并存储如此多的数据,就是为了进行大海捞针,可见大数据的价值密度之低。
并且,大数据的价值体现在对数据内部的相关性的挖掘,而非对因果性的求索。这个世界是复杂的,有相关性的事件之间不一定有直接的因果关系。
我们不必纠结于事件之间具体的前因后果,只要知道它们之间是有正向或者负向联系的,只需照着做就能体现数据分析的价值了。这是一种实用主义的态度。
举例来说,沃尔玛超市发现把啤酒和尿布放在一起时,啤酒的销量会大幅增加。此时摆在老板面前两个选择:是继续研究苦苦研究这个现象内在的因果关系呢,还是赶紧所有门店都如此配置起来好更快地赚钱?
答案显然是后者。大数据分析是用来发现相关性来创造价值的,而非探索因果关系进行科研。
大数据有哪些用处?
1、用户画像
「千万人撩你,不如一人懂你。」在现实世界里,唯一懂你的TA就是默默关注着你的大数据。
你的一举一动,都被各种APP记录下来并进行分析,找出典型特征,并据此跟你打上各式各样的标签。这些标签汇聚起来就是你这个人在网络上的化身,美其名曰「用户画像」。
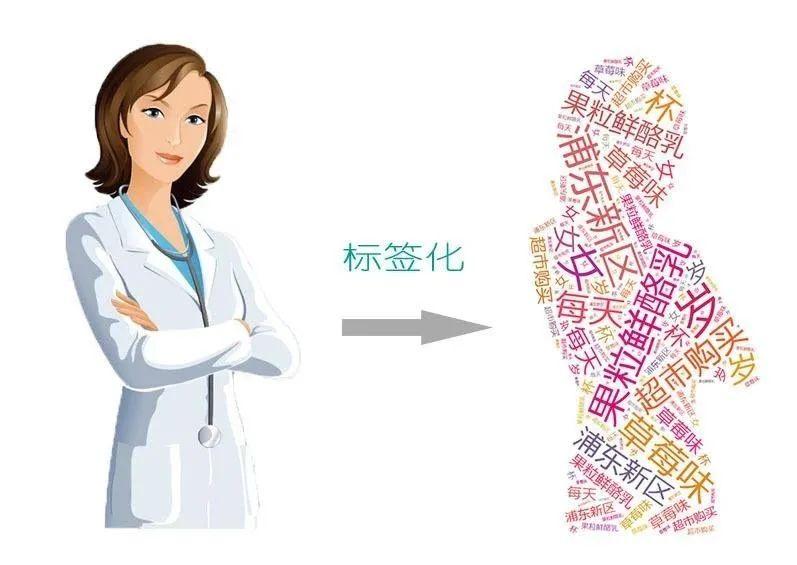
通过搜集并分析多维数据,这些用户画像可以包罗万象,每一个用户在大数据面前都是一丝不挂的。基于对用户的了解,各种各样的精准营销就可以高效进行了。

如此一来,你打开购物APP,醒目位置显示的都是自己想要买的东西;打开资讯APP,头条里面推荐的都是自己偏好的内容;打开搜索引擎,搜出来的东西都正好是自己想要找的。
亚马逊技术专家曾经说过:「如果系统运作良好,亚马逊应该只推荐你一本书,而这本书就是你将要买的下一本书。」
2、决策支撑
在移动通信领域,所有用户产生了海量的信令交互,网络测量报告,以及各种各样的业务数据。
这些信息都是被记录下来的,除了可以用来追踪用户,解决故障之外,还能用来了解自身的网络覆盖,容量,用户满意度等指标,并能和对手进行对比分析。
基于这些大数据的分析结果,网络优化,用户体验提升等操作都可以有的放矢,更为方便高效。
在医疗领域,大量患者产生的海量数据可以用来进行临床治疗对比,药品研发,疾病诊断,甚至还能作为医保政策,额度等调整优化的依据。
除了上面的例子之外,大数据还在互联网,金融,以及各种垂直行业内部都有着丰富的应用场景。总结起来就是「知己知彼,百战不殆」,「运筹帷幄,决胜千里」。
大数据和云计算,人工智能及5G之间有什么关系?
由于大数据分析需要对大量的数据进行分解,统计,汇总,一台机器肯定搞不定,于是就有了分布式计算的方法。
也就是说,将大量的数据分成很多的小份,每台机器只处理其中的一小份,多台机器并行处理,处理速度得以大幅提升。
例如著名的Terasort对1个TB的数据排序,如果单机处理,怎么也要几个小时,但并行处理,仅需要209秒即可完成。
在分布式计算框架下,大数据的处理,可以分为数据收集,数据存储,数据处理(资源管理与服务协调,计算引擎),数据分析,数据可视化这几层。
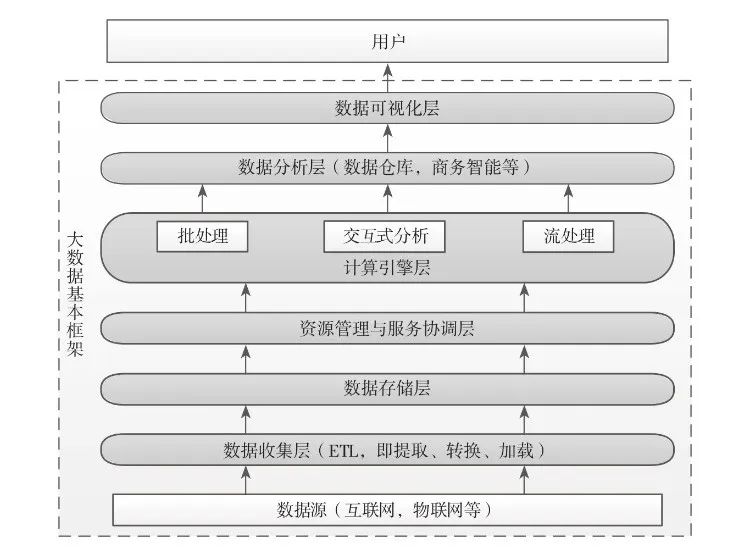
大数据需要大量的服务器资源,但这些资源可能并不是随时都满负荷工作的。例如使用大数据来分析公司的财务情况,可能只需一周分析一次,但把这成千上万台机器放在机房里,每周用一次是非常浪费的。
这正是云计算诞生的初衷。如果能在不同的时间,把这些闲置机器提供的网络,存储以及计算能力共享给其他公司使用,资源的利用率将大大提升。
云计算通过硬件资源的虚拟化,相当于平台的提供者,而大数据是海量数据的高效处理,相当于云计算平台上的大型应用。
那大数据和人工智能有没有关系?实际上,大数据是人工智能发展的前提。
目前人工智能的主流算法是深度学习,其能够大展身手需要两个条件:强大的计算能力和高质量的大数据。其中最具有代表性的系统,就是著名的「谷歌大脑」。
这是一个庞大的深度学习计算框架,拥有数万台高性能的计算机和顶级图形处理器组成的计算单元,可以完成大规模,多维度,多层次的深度学习模型训练。
据悉,在谷歌大脑建立不久,谷歌就使用了一个拥有16000的CPU组成的超大规模计算机集群,让机器用深度学习模型自己「看」了一千万段视频,终于把人工智能训练地学会了如何从视频中辨认出一只猫来。
因此,没有大数据所提供的足够的学习样本,深度学习系统搭建得再完美也没用。可以这么说,深度学习算法是灵魂,云计算是肉体,大数据则是粮食。
没有粮食,肉体和灵魂就都成了空中楼阁。只有这三者合力,才能揭开人工智能应用的新篇章。而5G提供的万物互联,正是人工智能的粮食——大数据产出的肥沃土壤。
这就是大数据和云计算,人工智能,以及5G之间剪不断理还乱的联系。
好了,本期的内容就到这里,希望对大家有所帮助。
1、本文内容及相关资源来源于网络,版权归版权方所有!本站原创内容版权归本站所有,请勿转载!发布者:笑笑考吧,转转请注明出处:https://xiaofangkb.com/19448.html
2、本文内容仅代表作者本人观点,不代表本网站立场,作者文责自负,本站资源仅供学习研究,请勿非法使用,否则后果自负!请下载后24小时内删除!
3、本文内容、文字、图片等,仅供参考使用,本站不对其安全性,正确性等作出保证。但本站会尽量审核会员发表的内容
4、如您认为本文内容侵犯了您的权益,请与我们联系!我们将在5个工作日内做出处理!本站保留全部修改、解释、更新本声明的权利
 微信扫一扫
微信扫一扫 





